The Fourth Industrial Revolution: How Big Data and Machine Learning Can Boost Inclusive Fintech
The lending and credit scoring sector have more data than ever before at their disposal. How they leverage this data to create value for their clients and social impact determines the outcomes they can achieve in the financial services space.
What is ‘ML’ and Why Should I Care?
In 1959, Arthur Samuel, a pioneer in the field of machine learning (ML) and artificial intelligence during an era when computers filled an entire building, defined machine learning as “a field of study that gives computers the ability to learn without being explicitly programmed.”
During a recent keynote, Microsoft CEO Satya Nadella referred to data used in this context as “the new electricity,” calling our current era a “fourth industrial revolution” following steam, electricity and digital technology. Scott Guthrie, Microsoft executive vice president, also acknowledged that data is “enabling every business to be the disrupters of their industry by harnessing the power to drive insight from this data.”
Today, it is easier and cheaper to generate data than ever before, and the tools to turn these data into insights are growing exponentially in both quality and quantity. So much so that any organization dealing with data that does not apply ML in some fashion will be left behind.
The adopters of these tools have typically been rewarded for their efforts with more engaging, targeted and useful product features, reduced costs and increased revenue. In short, machine learning, when properly applied, has the ability to provide a significant competitive edge for an evidence-based outfit.
A sampling of cloud-based providers of machine learning as a service (MLaaS) and select use cases.
destacame.cl: A Data-Driven Fintech Startup
The Catalyst Fund (CF) team has been working with Destacame.cl, a fintech startup that is embracing this ML-driven future with open arms, to learn how ML could improve the way Destacame.cl identifies good and bad payers based on a score.
Based in Provedencia, Chile, Destacame.cl is focused on helping unbanked individuals gain better access to mainstream financial services via the digitization of alternative data sources like utility bills, automotive credit history, census data, airtime payments and more. These data serve not only to provide a proxy to the recommendations of traditional credit scoring models, but also to complement current credit scoring algorithms. In that sense, the company allows individuals to earn access to small lines of credit by essentially becoming a “credit bureau of one.”
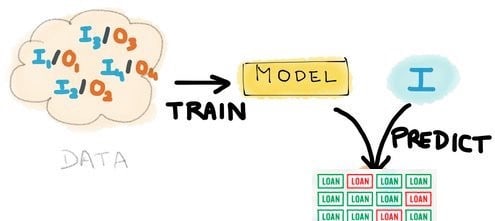
A basic sketch of the scoring process: Using historical data (labeled as “DATA” here) to train a model, which then can use new incoming data (labeled in the blue circle as “I” here) to predict results.
The current scoring process starts with a user who is looking to get better access to credit. The user signs in to Destacame.cl ’s platform, identifies him or herself, and can automatically upload his or her payment history. This is possible because the company has a connection to almost every utility company in Chile. These data points, combined with other data sets, are used to seed the proprietary algorithms (reflecting the most statistically significant indicators) that power the predictive credit-profiling model. The output of these algorithms is Destacame.cl’s score that rates the user’s likelihood to repay a loan in full to a lending bank. The score represents how responsible the user has been with their payments in the past 12 months, said CEO Sebastián Ugarte.
Additionally, Destacame.cl allows its users to access their credit report for free, so people can check out their financial health and understand their chances of getting a loan.
The score and the credit reports are then used to determine which financial offerings can be unlocked and accessed via Destacame.cl’s website. This web application also provides active guidance to individuals on how to build their score by connecting additional data sources, building better habits, etc., in order to gain access to even better product offerings.
The Hypothesis – What We Believed
With all these great features, there were still some areas within Destacame.cl’s processes that had not yet been optimized. When we first met, the company was using handmade statistical models and had not yet fully incorporated machine learning into their score.
Our hypothesis at CF was that by introducing ML algorithms in place of their existing statistical models, we could realize the following improvements to their business:
- Time saved via automation: For Destacame.cl and for most startups in general, bandwidth and budget are always major considerations, and any progress in automating the modeling process translates directly to more resources available to focus on the product roadmap.
- Higher revenue via fewer defaults: For the bank, lowered rates of delinquency and default mean higher net revenue for known market segments, and potentially the ability to experiment with market segments and subsegments hitherto not targeted.
- Better recommendations via improved models: For the customer, better models that incorporate ML should translate to better financial advice and access to more products that may better suit pressing needs.
Enhancing the Product with Machine Learning
Our goal at CF was to enhance Destacame.cl’s ability to more precisely predict who will default based on individuals’ historical financial behavior. Statistically speaking, making this improvement meant that we wanted to implement an ML algorithm that would:
- Improve sensitivity (true positive rate), or maximize the correct identification of loans that will eventually default.
- Reduce Type 1 error (false positive rate), or minimize the number of good applicants that are identified by the model as likely to default.
- Reduce Type 2 error (false negative rate), or minimize the number of applicants who are likely to default but are identified by the model as good applicants.

Destácame’s Sebastián Ugarte (standing) and Macarena Silva strategizing with BFA’s Ashirul Amin and Matt Grasser (at the computer) in New York City around an enhanced data-driven credit scoring process.
The Process – What We Did
In order to accomplish these tasks, we laid out the following framework for our analysis:
- Replicate Destacame.cl’s proprietary existing statistical model’s results, examine any inherent assumptions and assess what improvements can be made.
- Train new credit delinquency/default ML models against the historical data with machine learning techniques explained below, then use these models to quantify improvements, and finally note any effects outside the direct objective that could affect the business model. In other words, use the historical data to quantify and better predict future customer behavior.
- Translate from abstract improvements in the statistical model to concrete revenue increases in the business model via a return on investment (ROI) model. The idea here is to take the predicted customer behavior and turn it into an expected net revenue for the product within the financial institution.
The Results – What We Learned
The first step of replicating the historical data proved successful. Within CF, we were able to validate the results of Destacame.cl’s previous analyses, and get clarification on a few of the assumptions that went into the creation of their scoring method.
The second step of training the ML models also proved very successful, and a breakdown of the approach is the subject of the rest of this post.
Details of the third step of translating these statistical models to build ROI business models will be explored further in a future post.
Choosing and Training ML Models
Step 1: Logit. We began by training and testing a logistic regression (logit) model, which is arguably the most common ML approach for generating classifications (e.g. a Destacame.cl credit score) using quantitative input variables (e.g. past payment data). Using this approach as a litmus test for the efficacy of ML versus the existing scoring methods, we produced the following results:
- Increased sensitivity: Model sensitivity was improved to 67 percent compared to 34 percent using the previous Destacame.cl labels. Success.
- Reduced Type I error: Using the initial Destacame.cl labels, 34 percent of what would be current loans would be misidentified as likely to default, and would not make it through the vetting process. The introduction of a logit model reduced this error to 21 percent. Success.
- Reduced Type II error: Of the loans that were identified as current during tests using the initial Destacame.cl labels, 66 percent were defaulted loans that were erroneously identified as current. Only 33 percent of loans identified by the logit model as current during testing actually defaulted. Success. (Editor’s note: Type I and Type II errors were updated Feb. 2, 2017.)
These were quite encouraging results. The success of the logit algorithm illustrated the ability of ML to create significant improvements over the existing scoring algorithm. Implementation of this model in production would likely translate to a significant savings for the banks, as well as reduced risk of default for individual loan recipients, and the repercussions that come with it.
Step 2: Decision trees. Building on logit as an ML baseline, we decided to explore a number of tree-based machine learning techniques as well, namely: regression trees, conditional inference trees, evolutionary trees and random forests. Each was chosen for its relative strengths.
Overall, we saw comparable results, with conditional inference trees providing a slight improvement in sensitivity and Type II error, at the expense of increased Type 1 error:
- Increased sensitivity: 67 percent for logit compared to 69 percent for conditional inference trees.
- Reduced Type I error: 21 percent for logit compared to 25 percent for conditional inference trees. Noted as a tradeoff.
- Reduced Type II error: 33 percent for logit compared to 31 percent for conditional inference trees.
Simply, this means that these trees are better than logit and therefore the initial model at predicting delinquencies, but will turn away more good loans than logit as a result.

A highly exaggerated example of before and after a properly-trained machine learning model is introduced.
Step 3: Interpreting the results. For a risk-averse financial institution, these tradeoffs that the tree model presents could be a good thing. For an institution with a higher risk tolerance, perhaps the logit model is a better choice. For yet a third bank, perhaps some mix of the logit and trees (i.e. an “ensemble” model) would be best. The details of this decision are best examined using a formal ROI analysis, which will be covered in our next post.
One thing is clear here regardless of the final model choice between logit and conditional inference trees: Machine learning has produced substantially better results than the already successful existing model, for everyone involved.
Takeaways for Our Learning Agenda
- With machine learning, great power means great responsibility. ML is a powerful tool that allows us to extract intelligence above and beyond what other approaches, like manually generated classifications, can do. However, ML is not a silver bullet and does require some careful consideration prior to a final choice of model.
For this analysis, specifically, we saw a case where improving our sensitivity meant increasing Type I error. Some institutions will happily accept that tradeoff, while others would be happy with logit’s improvements over the existing scoring methods. The only way to choose which model is best is to understand the context in which it will be used, and build a financial model that makes the criteria for that decision explicit.
In short, ML is great, but to really shine in its effectiveness, it also requires good technologists and a good understanding of how to model in the context of business and customers.
- This is a constantly evolving field. ML has made and continues to make great strides since its inception in the ’50s. Both quantity and quality of data being generated have increased in the digital era, and as it continues to democratize through Machine Learning as a Service (MLaaS) platforms and the like, we’ll see improvements in the availability and variety of applications and modeling techniques that can be used to solve problems like this one.
- Follow the data. By paying proper attention to any of the data we generate, and training machine learning models to recognize significant patterns, we are effectively creating feedback mechanisms that allow for incremental improvements across any imaginable range of cases. Perhaps the kinds of data sets we work with and the refining of the ML algorithms for the low-income customers in emerging markets has implications for reverse innovation for mainstream fintech and other data-heavy and customer-centric industries in established markets.
- Steal this framework! (But remember the devil is in the details.) This is one very successful story of a fintech startup using ML to focus on credit products for the underbanked, and one that has its own share of specific goals and nuances and constraints. However, the general framework discussed above (replicate, train, then translate) is not necessarily limited to this particular application. Assuming that the proper data is available, a good technologist is owning the implementation, and that the right context is considered for the particular problem at hand, this approach can potentially be applied to startups across a variety of spaces who are looking to improve on data-driven solutions in their own right.
Matt Grasser is a senior associate at BFA.
Photo: While Arthur Samuel was busy defining machine learning, ENIAC, the first modern (“Turing-complete”) computer, pictured here, circa 1947, was being heralded as a “giant brain” by the press. Credit: Dennis S. Hurd, via Flickr.
You May Also Be Interested In:



- Categories
- Finance, Technology
