How Artificial Intelligence Can Simplify International Development Research: An Intriguing Experiment (Involving NextBillion)
Anyone working in international development can spend large amounts of time trying to keep up with news about their area of activity. Researching evolutions in practice, scanning the latest country or industry reports, identifying trends, or simply staying abreast of professional gossip can require a lot manual labor.
We’ve known for some time that much of this can be automated and aided by artificial intelligence (AI). What we haven’t known with any certainly is what those “automatable” tasks are and how they can be carried out. At least until now.
At BFA, we’ve had a good bit of experience working on issues at the intersection of development and technology. We decided to leverage this expertise to answer the question: How can we use technology to sift through the vast amount of development-focused content online, to help people reduce time and labor and learn more, and more efficiently? The answer takes a bit of technical explanation, but it opens up exciting new possibilities for development professionals.
Topic modelling as the tool of choice
Any particular subject area in international development may generate vast amounts of quality content in the form of blogs, briefs, and other types of literary material. We decided to sort through this content with the help of Natural Language Processing (NLP) technology. NLP is used to help computers understand humans’ natural languages, and it thrives off of large quantities of data.
There is a class of NLP algorithms known as topic modeling algorithms. They help to organize documents into different “buckets,” where each labelled bucket contains documents about similar topics. If there was an accurate topic modeling algorithm for information about development practices or innovations, human reviewers could see whether a particular topic or concept was featured in a piece of content. With hundreds of articles and reports generated each day, this could serve as a valuable time-saver to weed out content that is definitely not relevant, while flagging content that very likely is.
The outcome of most topic modeling algorithms is to take a document and tag its topics. We chose an algorithm called Latent Dirichlet Allocation (LDA), an effective algorithm for this sort of modeling, with many available libraries in the Python programming language. To get up to speed, the algorithm first needs to be “trained,” using a large dataset of documents that are about similar or related concepts. That’s where NextBillion comes in.
Generating a corpus with content from NextBillion
For our training corpus (the collection of documents), we used blog posts that appeared on NextBillion between September 2011 and January 2019. We chose NextBillion because: a) its blog posts cover a wide array of development issues; b) the content is publicly accessible; and c) each blog post already has a number of manually tagged categories such as health care, education, etc. that are helpful for validation.
Here’s how we trained our LDA algorithm on the NextBillion blog posts. We began by generating 10 subject-matter topics from the corpus, four of which are shown in the table below as an example. These topics were chosen because they match up with some of the most commonly used NextBillion categories, shown in the first column of the table. Each topic is represented by a weighted list of words generated by the LDA algorithm, and based on words that appear frequently in the NextBillion articles about those topics, as shown in the second column of the table. We then manually named the topics based on their word composition, as shown in the third column of the table.

Once we had our 10 topics established, we were able to show the model new NextBillion articles and obtain a weighted list of likely topics of those articles, such as:
0.74*”Health Care” + 0.19*”Entrepreneurship” + 0.07*”Farming”
The LDA algorithm assigned a probability to each topic, signified by the corresponding numbers. For example, using the article that generated the topics above, there is a 74% chance that this article is about health care, a 19% chance that it is about entrepreneurship and a 7% chance that it is about farming.
What we found
We then ran an experiment to determine how our topic modeling with AI compared to the manual categories assigned to the blogs by NextBillion’s editors. For example, we compared four categories that NextBillion editors had manually created to the categories created by LDA topic pairings.
The frequency of each category-topic pairing over time is shown below, where NextBillion categories are the blue lines and LDA topics are the orange lines. If the LDA algorithm is working effectively (and the NextBillion editors are equally effective at assigning accurate topics to the articles), you’d expect to see similar trajectories in the two lines.
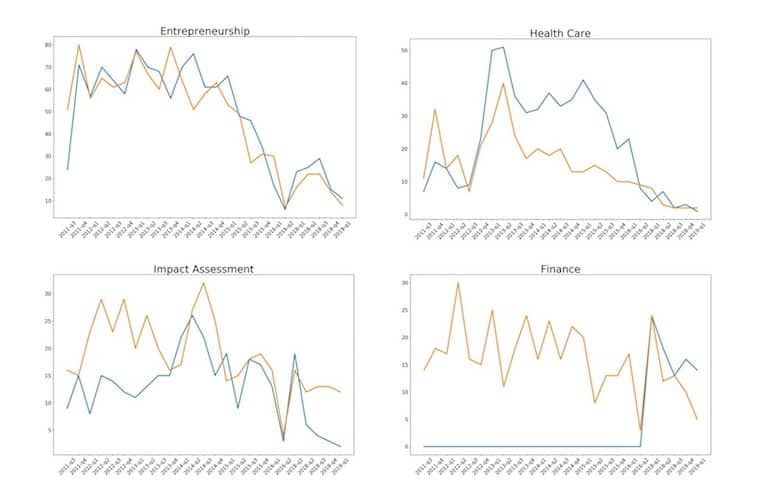
As you can see, in general, the entrepreneurship and health care topic-category pairs match up well, and impact assessment doesn’t seem too far off. Finance is a clear outlier, but we think there’s an explanation for that. NextBillion did not begin to use that category tag until early 2016, which brings us to the discussion of the use case.
Use case: What were people really talking about?
Regardless of why NextBillion began to use a finance category only in early 2016, it’s unlikely that prior to that there were no finance blogs at all on the platform.* Thus, our initial testing demonstrated that LDA can be quite helpful in identifying blog topics – even when no manual categorization exists.
These results showed that there is already value to this algorithm when analyzing websites without an existing manual categorization. But we can see how it could be useful even when analyzing a content platform with categorization, if certain categories aren’t formally made available to readers until months or years after the relevant content is published.
How does this value translate to actual practice? For one thing, locating the first mentions and histories of widely used techniques often requires significant manual labor which could be greatly reduced by this technique. To use a common example from the development space, the term “financial inclusion” was not common among development professionals 10 years ago. The common terms then were “microfinance” or “microsavings.” By using LDA to facilitate this kind of research, it would be possible to locate content relevant to financial inclusion based upon the presence of other words in the articles – even if the term “financial inclusion” is never mentioned.
Essentially, this technology is useful whenever there’s a huge amount of text data/documents that need to be combed through. Another good use case, then, would be if there are many documents on a subject and a researcher needs to eliminate a subset of those documents that they know are not relevant to the subject at hand. (Along with detecting the topic of written content, LDA is also good at determining when a topic is not being discussed in the content.)
The technology can also be used to supply initial topic tagging for a set of documents that lacks it – a use that would definitely be helpful for academics who need to scan through a large corpus of old documents or reports that were filed without any sort of categorization.
There are many available open source tools that can implement the LDA algorithm, along with many other NLP algorithms. These tools are released for free (with documentation) by companies like Google and OpenAI, and are aimed at facilitating development efforts through programming tools and libraries. When combined with the treasure trove of content that the development space generates, they can greatly improve practitioners’ ability to provide value to people in emerging economies.
With every blog post, article, or report that gets published, a new piece of data is generated. Each piece of data can serve as fuel for an algorithm which, with the right guidance, can augment and improve the inherently human process of research.
It’s easy to see, then, why artificial intelligence is here to stay, with rich datasets being a key component of its effectiveness and usefulness. To see more work that BFA has done with AI, please visit our website for a report on how AI can benefit fintechs and financial service providers working with low-income consumers in Africa.
*Editor’s note: NextBillion underwent a site-wide redesign that was launched in late 2015, and in early 2016 we revamped our categories to better clarify site navigation, which included the addition of a finance category alongside our existing Financial Health sub-site and multiple finance-related tags. There were certainly finance blogs on the site prior to that time, they just weren’t categorized in the same way as other content.
Jacob Rosen is an associate and Ashirul Amin is a senior associate at BFA.
Note: BFA is a NextBillion partner.
Photo courtesy of Element5 Digital.
You May Also Be Interested In:



- Categories
- Finance, Technology
