Using AI to Transform Impact Measurement: Overcoming Language Barriers in Global Development Research
Warren Buffet has a phrase he uses to describe those who were born into a state of relative privilege — that they won the “ovarian lottery.” Generally speaking, those who won the ovarian lottery are the ones who are trying to provide poverty-eradicating assistance to those who did not. But there are almost always language and cultural barriers that create a “listening divide” that impedes understanding between the two groups. Unless they’re able to bridge this listening divide, diagnoses of and solutions to poverty-related problems can be ineffective.
Artificial intelligence (AI) can play a key role in bridging this divide. In recent months, ChatGPT has captured the world’s attention as the first AI platform intuitive enough to gain mainstream uptake, sparking a flurry of wonder, doubt and experimentation. But the technology built by ChatGPT’s forerunners has been used for some time in industries such as finance, human resources, marketing, telecoms and cybersecurity. Along with ChatGPT itself, these years of experience provide important lessons for how to use the new generation of predictive (as opposed to generative) AI to bridge the listening divide by deciphering transcribed natural language.
We’ll explore some of these lessons below, discussing how these emerging AI tools are already impacting our poverty alleviation work at Decodis — and highlighting the role human intelligence must still play in guiding these efforts.
Before ChatGPT: Our Initial Experiences with AI-Based Tools
Decodis is a social research company that provides diagnostic insights into the range of challenges faced by vulnerable populations. The cornerstone of our methods is the power of natural speech, and the technology that supports voice collection and analysis. We utilize this technology to enhance our clients’ research, which can inform their efforts to conduct social programming, policymaking, impact measurement and other activities.
A big part of our work involves optimizing survey data collection, to understand not only what people say but how they say it — a process that can better reveal their experiences and perspectives, highlighting the ways organizations can serve them more effectively. After a survey participant answers a set of open-ended questions, we convert the audio captured into text and then analyze that text to sift out consistent themes and topics. This process illuminates valuable insights, but it is too labor-intensive to do without AI assistance. We collect this survey data from thousands of respondents, which typically generates over 100 hours of audio in many different languages — far too much for a researcher to do manually.
To streamline this process, we use Natural Language Processing (NLP) to analyze these recordings, a tech-driven method that allows us to process as much text in two days as a qualitative researcher could process in two months. We have been on a long journey to find a tool that can support our NLP efforts, analyzing those many hours of audio to classify them into different themes. We started simple, using rule-based topic classification offered by several off-the-shelf products. These products helped us to classify text into different categories based on our own handcrafted rules. However, we were frustrated that there was no way to calculate the accuracy of these types of models, which stymied our efforts to find ways to make them more powerful. To understand some of the more nuanced topics relevant to the developing world — such as financial inclusion, gender norms and economic empowerment — we needed more flexibility.
We were able to find more sophisticated NLP models on an open-source AI platform called Hugging Face (whose unique name apparently comes from an emoji). These models were not as user-friendly as off-the-shelf products, which have more intuitive user interfaces — but our engineers could easily adapt them to fit our needs. A set of multi-label transformer-based AI models was a particularly important feature for us: These opened the door to models that could “learn” — i.e., improve their ability to understand text by “practicing” on similar text until they fine-tune their processing. In the process of analyzing text, these models successfully corrected their own wrong answers while reinforcing their right ones. But again, there were shortcomings. For instance, these AI models were only able to identify one topic from a piece of text. So if the text said, “my cassava crop failed so I needed to borrow money to pay school fees,” the models were only “smart enough” to tag it as talking about agriculture, when it was also important to our data categorization efforts to know that the text mentioned financial products and educational expenses. So these tools still did not have the power to support our objectives.
Then, in November of 2022, OpenAI introduced ChatGPT. ChatGPT was built on a huge amount of data, but it also has the ability to develop conversational memory, in which the AI learns words in part through the context in which they appear. If the right context is provided by a topic expert, the amount of data required to train ChatGPT’s model for text analysis is not substantial. With strong context-setting alongside a growing corpus of topic-specific training data, we at Decodis are now using ChatGPT to achieve higher accuracy than ever before. Most of our NLP models are now performing at levels upwards of 95% — in other words, these models are able to correctly understand the meaning of text more than 95% of the time, compared to 60-70% with other models we’ve tried.
Keys to AI-Powered NLP: Lots of topic-specific data and keeping a ‘human in the loop’
The best data sets for context-relevant modelling — i.e., AI models that can be trained to recognize the meaning of text based on the surrounding context — come from natural language, which Decodis collects through voice-led surveys. This means we have an ever-increasing amount of data which we use to train these AI models. The more we run these models on new data, the higher their accuracy — in essence allowing us to create in-house models specific to topics related to poverty alleviation.
The performance of these models is not only driven by a bounty of recorded natural language, it’s also improved through a process which involves human-led context setting. In this process, a qualitative researcher — the “human in the loop,” with expertise in the topic at hand — manually categorizes a small set of responses to show ChatGPT how to pick up what we want to know from that text. In essence, we provide the building blocks of the conversations on which the AI model is trained, before we use it to analyze more text. It can then be used on larger sets of data, with the researcher making tweaks so the model learns again and increases its accuracy even more. The table below provides an example of this process for one small snippet of text. The contextual information in the columns is provided by a human familiar with financial inclusion, to provide the notions the NLP models should be looking for. This kicks off a training process through which the NLP models become increasingly “smart” about how to look for relevant financial inclusion notions within the text.
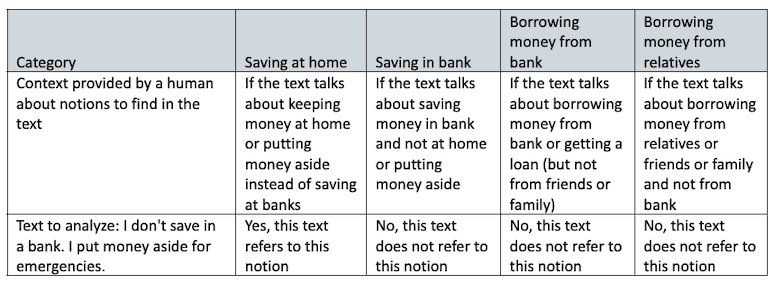
This is, in essence, a process of supervised artificial intelligence, where we are initially directing the output according to our expertise. At first, there is human involvement in giving the input, to ensure the AI is trained to give the right output. If the context and information are not given in the right format, the accuracy will drop and the model will spit out false information, just as ChatGPT tends to do when fed with inaccurate data. To avoid this, human direction at the beginning of the process is critical, to ultimately train a model to work with the highest accuracy — an essential quality if we are to fully bridge the listening divide between development professionals and vulnerable populations.
Though AI-based tools have already had an impact on our work with NLP, their benefits are likely to grow as these technologies continue to develop. One remaining question is how soon we will see a version of GPT that can be used to understand text directly in the wide variety of languages used in the global development space. After all, translating a foreign text to English often results in a loss of context and nuance, and therefore it is far better to use NLP directly on local languages. The next version of GPT — GPT–4, which has been released in limited form — has been tested on 26 languages, including several low-resource languages that have limited amounts of data to train AI models, such as Swahili, Punjabi, Marathi and Telugu.
However, though the models for these languages have been tested on small amounts of data, they have not been trained on larger sets of natural language data. As Decodis expands our corpus of low-resource language text, using local language experts to tag specific phrases relative to different development contexts, we can train increasingly accurate AI models for these languages. But for other languages like Luo, Twi and Xhosa, which have even smaller amounts of training data and are unlikely to be included as language models for AI in the near-term, we will have to look to the future once again — or solve this problem ourselves.
Daryl Collins is the CEO and Founder, and Pravarakya Reddy Battula is Director of Data Analytics, at Decodis.
Photo courtesy of Focal Foto.
You May Also Be Interested In:



- Categories
- Technology
